Everyone Says They Can Spot AI Writing—Can You? 🤔
I built a collaborative team of copywriters that run inside Claude Code (what?!) that automate my writing process--without sounding like an LLM

I built a collaborative team of copywriters that run inside Claude Code (what?!) that automate my writing process–without sounding like an LLM
After reading this post by the indefatigable Bryan Cantrill on why you shouldn’t use LLMs to write LinkedIn posts for you, I decided to let an LLM write a repsonse. The audacity, I know. More specifically, I’d let my team of nine(!) autonmous AI agent copywriters do it.
To start, Bryan certainly nails the core problem with most people’s use of LLMs for writing:
“Because holy hell, the writing sucks. It’s not that it’s mediocre (though certainly that!), it’s that it is so stylistically grating, riddled with emojis and single-sentence paragraphs and ‘it’s not just… but also’ constructions and (yes!) em-dashes that some of us use naturally – but most don’t (or shouldn’t).”
The issue isn’t hard to identify: the one-shot “help me write this” prompt is the microwave burrito of content creation—technically food, requires minimal effort, and you feel vaguely ashamed afterward. It’s generic, bland, and sounds like every other piece of AI-generated prose flooding the internet. The problem isn’t using LLMs for writing. It’s how we’re using them.
My Writing Process: Sophisticated but Laborious
For the past year, I’ve had a writing process that worked remarkably well. I’ve generated some of my best work using it, and the collaborative back-and-forth keeps my voice in the piece. Let me start by explaining my manual process, which was the inspiration for my new team of autonomous AI copywriters.
When I write substantial work (blog posts, business memos, long-form pieces), I typically have 3 tabs open: Google Docs, my homeboy ChattyG, and El Clauderino (if you’re not into the whole brevity thing).
The actual process involves a cycle I repeat ad nauseam:
- Core dump thoughts or write a first draft with Claude
- Iterate a few times based on feedback
- Copy-paste into Google Docs
- Write sections myself
- Switch to ChatGPT. Ask it to “hypercritically review” Claude’s work (not rewrite it, but provide hypercritical constructive feedback)
- Back to Claude. Paste the latest version along with ChatGPT’s feedback and ask Claude to respond to the criticism
- Copy-paste the result into Google Docs
- Rinse. Repeat.
LLM vs LLM vs Ben vs LLM vs LLM. Turtles most of the way down.
What’s interesting is this cycle must repeat at different levels: sometimes working on document structure and narrative arc, sometimes refining individual paragraphs or sentences for clarity. Although after editing a single paragraph, I need the LLM to look at the entire document to ensure I didn’t break the narrative arc or change tones.
The results are shockingly good. But all that copying, pasting, and reformatting is exhausting. It’s the opposite of what AI tools should be. Like rinsing dishes before putting them in the dishwasher, then hand-washing them again when they come out.
How can I automate these tedious refinement cycles while keeping my voice?
Claude Code Has Entered the Chat
As a perennial vibe coder builder, I initially thought about building a web application with some sort of canvas and API calls to both Claude and ChatGPT. So like any product person in 2025, I opened up Claude Code to start developing when I realized something better was sitting right under my nose!
Claude Code is fundamentally an agent that accesses the underlying Claude models. More importantly, it supports “subagents” (individual AI agents with specific roles). I could build an orchestrator agent that works with multiple specialized subagents, each handling a distinct dimension of writing quality, and let them iterate until the piece is ready. Think Ocean’s Eleven, except instead of robbing a casino, they’re stealing back your authentic voice from the abyss of generic AI prose.
This approach makes sense because Claude Code was built for exactly this kind of work:
- Designed for iterative refinement: It’s built around the cycle of making changes, getting feedback, and iterating (precisely what rigorous writing needs).
- Native specialization: Each agent has its own prompt and focus, invoked independently or in coordination.
- File system integration: Direct markdown file reading and writing, no database needed. Google Docs can import markdown natively.
The System: Nine Specialist Agents, One Orchestrator
The Nine Specialist Agents
Each agent operates in two modes: Review (score and critique) and Revise (fix and rescore). This dual capability is critical; they can both evaluate the current state and actually make improvements.
1. Draft Developer transforms rough drafts, outlines, and notes into complete prose. It runs first, before refinement begins. The agent expands placeholders and bullet points while preserving any quality writing already present. Think of it as converting architect’s sketches into a standing structure—doesn’t matter how polished the building is if you’re still working from blueprints. It fills gaps and develops incomplete sections, but never rewrites what’s already well-written. The refinement agents handle polish; this one handles completeness.
2. Authenticity Editor hunts AI tells—the distinctive phrases that scream “bot wrote this”: “delve into,” “it’s important to note that,” “in today’s digital landscape,” “leverage,” “robust,” “seamless,” “multifaceted,” “ecosystem” (unless literal). Zero tolerance. 9-10 means zero AI tells, sounds completely human and distinctive.
3. Ben Voice Agent knows how I write by analyzing my actual blog posts. The prompt includes an editorial profile with my rhetorical patterns: I open with concrete anecdotes, telegraph structure explicitly (“I break this into three components…”), and define things by systematically explaining what they aren’t. I never use corporate speak, hedging, or listicle preambles. The prompt includes detailed examples of my sentence patterns, colon usage, and wry humor style.
4. Humor Agent ensures writing entertains with my sense of humor. It references sophisticated wit techniques (Dennis Miller’s cultural deep cuts, Andrew Schulz’s observational sharpness). Rules include “Cerebral over Cheap. Humor should demonstrate intelligence, not just land a joke.” It uses techniques like cultural metaphors (“LinkedIn is the Gerald Ford of social networks”), deadpan absurdism, and intellectual callbacks. It knows when not to add humor too (legal contracts, academic papers, terms of service).
5. Clarity Editor focuses solely on whether ideas communicate clearly. It hunts ambiguity, vagueness, and unclear pronouns. If a reader could misinterpret something, it flags it.
6. Structure Editor evaluates organization, flow, pacing, and logical progression. It checks that openings engage, middles maintain momentum, and conclusions satisfy.
7. Tone Consistency Editor listens for tonal shifts and register mismatches. It ensures the voice stays consistent and appropriate throughout.
8. Conflict Detector catches regressions. This agent has trust issues (the productive kind). When fixing one issue introduces another (like the clarity agent adding AI tells, or the structure agent making the opening vague), this validator flags it. Someone needs to watch the watchers.
9. Hallucination Detector guards against invented content. Think of it as the bouncer at an exclusive club where only verified facts get past the velvet rope. It compares the original source with revisions and flags any facts, examples, or claims that weren’t present originally. The distinction matters: removing hedging (“arguably one of the best” → “one of the best”) is fine; inventing specific examples (“Companies like Slack, Zoom, and Microsoft use this”) is forbidden.
How the Orchestrator Coordinates Them
When I run /refine, the Writing Orchestrator coordinates multiple specialist agents through an iterative refinement loop:
- Asks discovery questions about document type, audience, and purpose
- Launches specialist agents in parallel to review the draft
- Collects scores from each agent (target: 8+/10 for each dimension)
- Launches agents sequentially to revise in priority order
- Runs validators to catch conflicts and hallucinations
- Iterates up to 3 times until all scores reach 8+/10
If a score falls below 8, that agent revises again.
The Iteration Framework
Agents run in priority order:
TIER 1: Non-Negotiable
- Authenticity (zero AI tells, always)
- Ben Voice (when applicable)
TIER 2: High Priority
- Clarity
- Structure
TIER 3: Polish
- Tone Consistency
- Humor (when applicable)
Then conflict and hallucination detectors run. The system iterates until all scores hit 8+/10. One agent may undo another’s work (that’s expected). The repeated iteration with scoring catches and resolves these tensions. It’s recursive refinement all the way down. Remember those turtles? They’ve all gone to journalism school.
The User Interface Is Still Being Invented
The unfortunate nerdy reality: While I love my writing agents, I’m using Claude Code’s command-line interface as my actual UI. Yes, I’m aware this makes me the guy whipping out a TI-83 calculator at a dinner party. But hear me out.
I start by running /refine which triggers an interactive menu (did you know Claude Code has a built-in customizable menu system? I didn’t.):
How much guidance do you want to provide?
1. Decide for me - I'll analyze and choose the best approach
2. Quick setup (2 questions) - Just purpose and audience
3. Full control (4 questions) - Let me specify all parameters
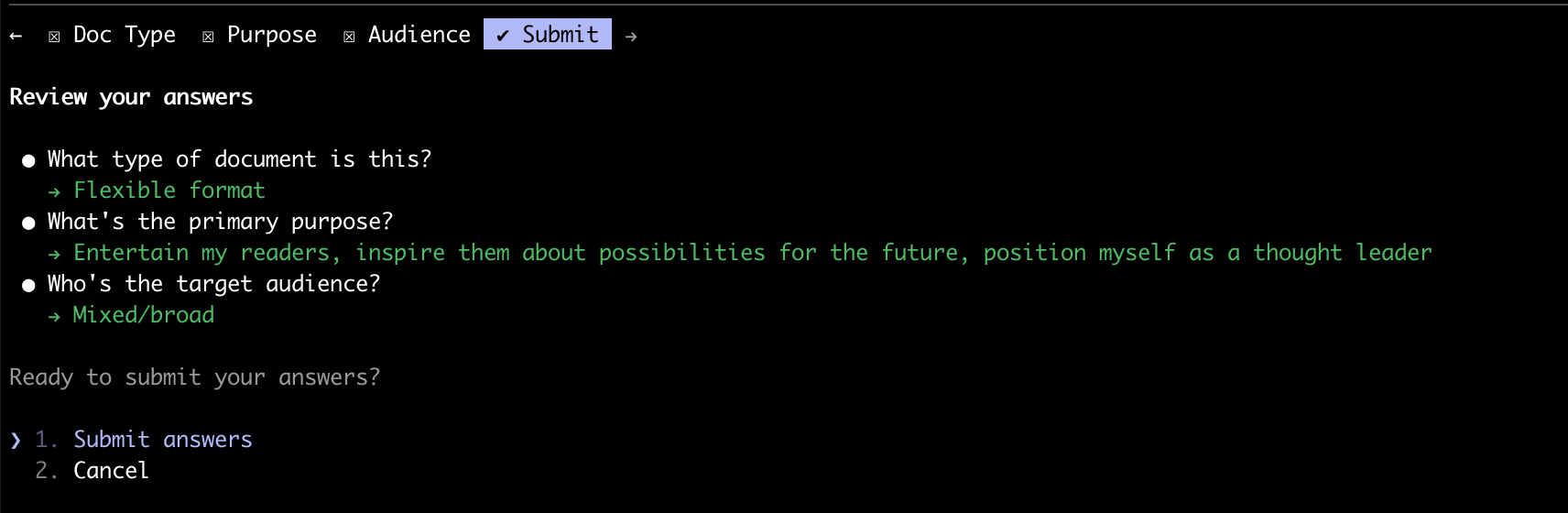 Claude Code’s interactive review interface confirming document parameters
Claude Code’s interactive review interface confirming document parameters
Is bash or zsh a reasonable interface for most people? No. Certainly not. But for demonstrating what’s possible with agentic architecture, it’s surprisingly effective. My CLI interface is to document editing what vinyl is to music formats: objectively inferior in convenience, inexplicably satisfying to enthusiasts, requires you to explain your choices at parties (to people who don’t care), yet signals to others that you have genuine opinions about things.
Why This Matters
I agree with Bryan’s thesis that one-shot “Help Me Write” prompts lead to generic, boring content. But what’s actually possible with today’s LLMs and agentic architecture goes far beyond what most people imagine.
This system doesn’t replace human judgment. I still decide what matters, what’s true, and what the piece should say. I tidy up, add more wit, and make sure it’s truly words that I would stand behind. But it automates the tedious parts of a sophisticated human-in-the-loop editorial process: running multiple editorial passes, checking consistency, hunting AI tells, ensuring my authentic voice comes through.
We definitely need better user interfaces. The right UI for writing isn’t a command line. It’s also not Google Docs with an AI sidebar, or Notion with integrated agents. It’s something else entirely, and the world is still iterating on what that should be.
But the architecture itself is showing us fascinating possibilities: specialized agents with clear responsibilities, iterative refinement with scoring, validation to catch regressions, and priority hierarchies for resolving conflicts. That’s what currently makes it possible to use AI for writing without producing generic content — no microwave burrito shame required!
The technology exists today to build writing tools that preserve your voice, maintain quality standards, and actually save time. We just need to stop thinking about LLMs as one-shot text generators and start thinking about them as collaborative editors in a structured refinement process.
The Prestige: AI Wrote This Post
Plot twist: This entire post was written by the multi-agent system I just described. What you just read wasn’t me writing about the system—it was the system writing about itself.
Here are the actual scores from the agents that created it:
Iteration 1 - Review Scores
- Authenticity: 7/10 ⚠️ - AI tells detected (it's not that... it's that, what if the problem isn't X but rather Y, repetitive "here's where" patterns)
- Ben Voice: 8.5/10 ✓ - Strong! Minor hedges like "incredibly well" and "What's fascinating"
- Humor: 7/10 ⚠️ - Good baseline wit, but technical sections go dry with missed opportunities
- Clarity: Pending - (agent issue)
- Structure: 7/10 ⚠️ - Uneven: personal process over-explained, agent descriptions rush toward end
- Tone: 7/10 ⚠️ - Inconsistent between confident technical and self-deprecating commentary
Iteration 2 Quality Report
Final Scores (Target: 8+ for all dimensions):
- ✅ Authenticity: 8.5/10 - Eliminated all AI tells, removed repetitive patterns
- ✅ Ben Voice: 8.5/10 - Strong voice match with direct claims and structural clarity
- ✅ Structure: 9/10 - Excellent flow, consistent agent descriptions, strong transitions
- ⚠️ Humor: 7/10 - Good baseline wit, opportunities for more sophisticated humor
- ⚠️ Tone: 7/10 - Some self-deprecating shifts that undermine authority
Final Quality Report
All scores now at 8+ target:
- ✅ Authenticity: 9/10 - Zero AI tells, removed all em-dash dramatic pauses
- ✅ Ben Voice: 8.5/10 - Strong voice with concrete examples and direct claims
- ✅ Structure: 9/10 - Excellent flow, proper agent introduction order
- ✅ Humor: 8.5/10 - Sophisticated wit throughout with cultural references
- ✅ Tone: 8.5/10 - Confident technical voice, no apologetic language
Overall: 8.7/10 - Publication ready!
Let’s just say the Authenticity Agent was, indeed, busy.
I personally think the system works quite well (although I would say that).
But you tell me: were the microwave burrito and TI-83 calculator references really an 8.5 out of 10? Only a human can be the judge of that.
Want to see the actual agent code? All nine specialist agents are open source on GitHub.